Python
PythonistaでiPhoneから株価をスクレイピング
Pythonistaには多くのモジュールがプリインストールされていて、スクレイピングに必要なBeautifulSoupも初めから使える様になっています。そこで、今回はiOSアプリのPythonistaを使ってiPhone […]
Filter by Category
Pythonistaには多くのモジュールがプリインストールされていて、スクレイピングに必要なBeautifulSoupも初めから使える様になっています。そこで、今回はiOSアプリのPythonistaを使ってiPhone […]
DjangoのWEBプリケーションでCSVをpandasで読み込んでforで一行ずつループ処理をしたところ、毎回決まったところで決まったエラーが出たのでPyCharmのデバッグ機能を使って原因を調べた内容です。 プログラ […]
Pythonであるフォルダ内のファイルを別のフォルダにコピーする方法です。 ディレクトリ構造(ファイルのコピー後) directory = (os.getcwd())現在のディレクトリを取得します。 image_path […]
globモジュールを使いディレクトリ内にあるファイルを取得する方法です。 ディレクトリ構造 まずはディレクトリ内のjpgを全て取得します。 directory = (os.getcwd())で現在のディレクトリのパスを取 […]
Djangoのモデル上でDateTimeField型のデータが今日の日付のデータを取得する方法です。 1つ目00:00:00から23:59:59までの範囲を条件に取得します。 2つ目今日の日付が含まれるものを条件に取得し […]
テキストファイルやCSVファイルに書き出す時に文字コードをShift-JISに指定して書き出すとエラーになる場合があります。よく見るのが、-や を変換した時に出るエラーで\uff0dや\xa0と表示されます。 […]
DjangoでWEBアプリケーションを開発していてデータベースの集計などをバッチ処理したいときに、カスタムコマンドを作り実行する方法です。 今回はサンプルとしてmycommandアプリケーションを作成するので以下のコマン […]
DjangoのWEBアプリケーションでQuerySetの表示順を五十音順にしたら、開発環境では五十音順で表示されているのに本番環境では五十音順になっていないときの対処法です。(中途半端に五十音順になっていて、4、5件毎に […]
iPhoneとiPadから使えるPythonistaというアプリを使ってFlaskからHello World!する方法です。 Pythonistaはプリインストールされたモジュールが充実していて、バージョンも2.7か3. […]
Djangoでモジュールを作りviews.pyからimportして呼び出す方法です。 同じ処理を何度も書いたり、同じ処理を複数回呼び出したりするときは、その処理をモジュール化してviews.pyからimportして呼び出 […]
平素は格別のお引立てを賜り、厚く御礼申し上げます。 誠に勝手ながら、弊社では下記日程をゴールデンウィーク休業とさせて頂きます。 2019年4月27日(土)~2019年5月6日(月) 期間中お客 […]
DjangoでQuerySetで取得したデータをそのままpandasのDataFrameに変換する方法です。データを成形する必要がないときや、とりあえず全件CSV化したいときなどに便利な方法です。
株式会社ファントムは、2019年3月29日をもちまして設立1周年を迎えることができました。この節目を迎えることができましたのも、ひとえに皆様からのご支援の賜物であり、ここに改めて深く感謝申し上げます。 2019年3月 株 […]
Djangoのテンプレートに範囲を渡す方法です。指定した月の全日数を表示したいときや日毎に処理をして表示させたいときなどにrangeに範囲を入れてテンプレートに渡せます。 views.py 現在の年と月を指定して総日数を […]
Django上でPandasで作ったCSVをダウンロードさせる方法です。df.to_csv(“filename.csv”)でも出力は出来ますがダウンロードは出来ないので、ダウンロード機能が必要な場 […]
DockerでPHPの開発環境の構築をしました。普段の業務ではPythonを使うことが多いのですが今回はPHPの開発環境の構築ログです。簡単なPHPの動作を確認したかっただけなのですが、そのためだけにテストサーバーを用意 […]
リストをループで生成してリスト同士を計算する方法です。サンプルでは、[0, 1, 2, 3, 4]のリストを3個生成して計算します。 loopOneで3を代入しているのでリストを3回計算します。loopTwoで5を代入し […]
平成30年度群馬県よろず支援拠点 事例集にて弊社が紹介されました。 介護施設向け介護記録システムや施設内を人工知能で見守るAIカメラ「Casper」などを紹介していただきました。
2019年2月23日、24日にフィリピン行われた「PyCon APAC 2019 in Philippines」に参加してきました。今回のPyCon APAC 2019が初の海外カンファレンスであり、初めてのPyConで […]
データベースのバックアップファイルをAWSのS3に保存するプログラムを手動で叩くと問題なくS3にファイルが保存されるのに、cronで定期的に実行したらエラーが出るようになったので調べた内容です。原因はPythonのパスが […]

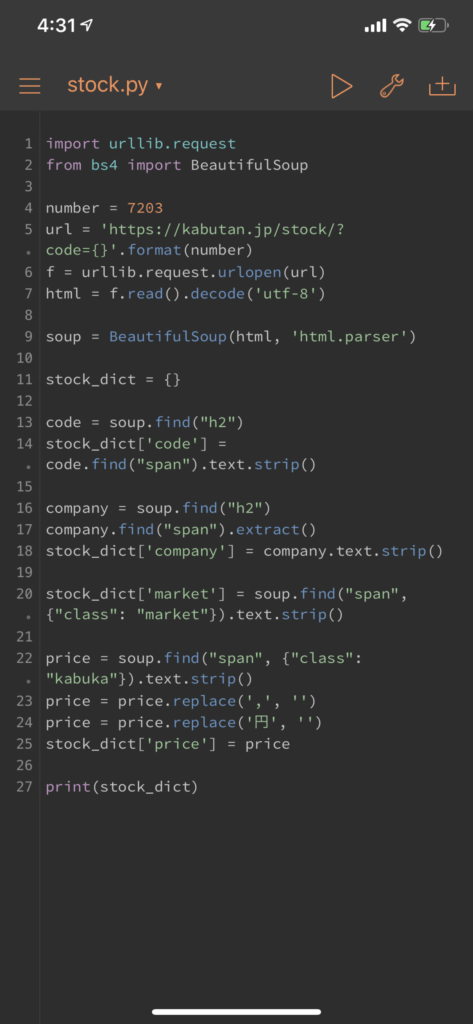
Pythonistaには多くのモジュールがプリインストールされていて、スクレイピングに必要なBeautifulSoupも初めから使える様になっています。そこで、今回はiOSアプリのPythonistaを使ってiPhoneから株価をスクレイピングします。証券コード、会社名、市場、株価を取得してみます。
stock.py
import urllib.request
from bs4 import BeautifulSoup
number = 7203
url = 'https://kabutan.jp/stock/?code={}'.format(number)
f = urllib.request.urlopen(url)
html = f.read().decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
stock_dict = {}
code = soup.find("h2")
stock_dict['code'] = code.find("span").text.strip()
company = soup.find("h2")
company.find("span").extract()
stock_dict['company'] = company.text.strip()
stock_dict['market'] = soup.find("span", {"class": "market"}).text.strip()
price = soup.find("span", {"class": "kabuka"}).text.strip()
price = price.replace(',', '')
price = price.replace('円', '')
stock_dict['price'] = price
print(stock_dict)
import urllib.request
from bs4 import BeautifulSoup
スクレイピング に必要なモジュールをインポートします。
number = 7203
url = ‘https://kabutan.jp/stock/?code={}’.format(number)
株価情報のページのURLを指定します。
(7203はトヨタ自動車の証券コード)
soup = BeautifulSoup(html, ‘html.parser’)
ページのソースコードをパースします。
code = soup.find(“h2”)
stock_dict[‘code’] = code.find(“span”).text.strip()
.text.strip()を使って<span>で囲まれたテキストのみを抽出します。
company = soup.find(“h2”)
company.find(“span”).extract()
h2タグ内に<span>タグが入り込んでいるため.extract()で<span>を除外します。
price = soup.find(“span”, {“class”: “kabuka”}).text.strip()
price = price.replace(‘,’, ”)
price = price.replace(‘円’, ”)
取得した株価情報には’,’と’円’が混ざっているので、replace()を使って数字だけにします。
取得・生成した情報はstock_dict = {}に代入していきます。
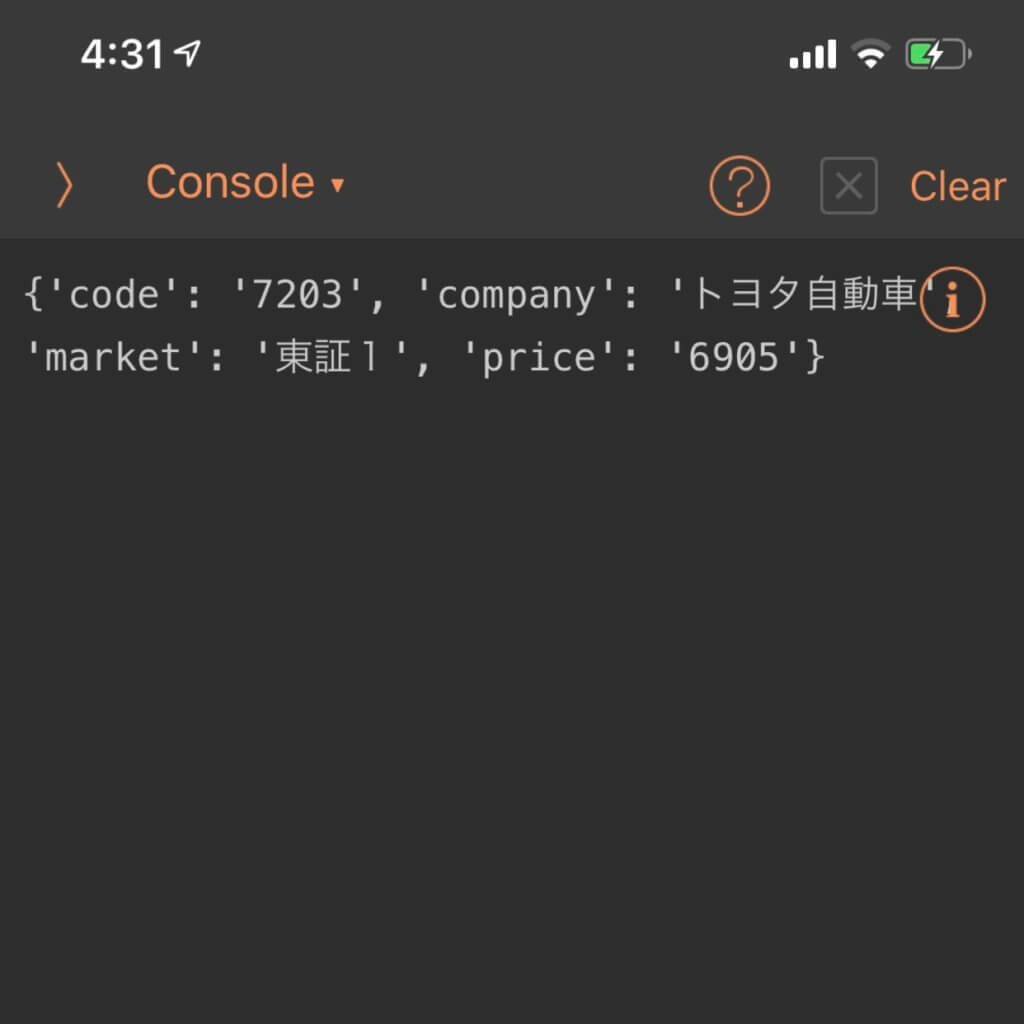
出力結果

群馬県でPythonを使ったAIやソフトウェアを開発している株式会社ファントムが運営しています。
Comments