Python
BERT+UMAPを実装した
https://shuhoyo.hatenablog.com/entry/nogizaka46-lyrics-nlp 上記サイトを参考にBERT+UMAPを実装してみた。 BERTとは BERTとは自然言語処理の1手法の […]
Filter by Category
https://shuhoyo.hatenablog.com/entry/nogizaka46-lyrics-nlp 上記サイトを参考にBERT+UMAPを実装してみた。 BERTとは BERTとは自然言語処理の1手法の […]
DjangoでPOSTとGETを組み合わせたパラメータでリダイレクト DjangoでPOSTを使ったリダイレクトはよく事例が見つかりますが、POSTとGETを組み合わせたURLにリダイレクトさせる情報があまりなかったので […]
WordCloudとは 文章に頻出する単語を抽出して画像に出力するシステムのこと。 実装について 形態素分析 まず形態素分析する必要がある。最新の形態素分析はJUMAN++なのでそれを導入すべし。 インストールするのは簡 […]
PyCharmでPostgreSQLをGUIから操作する設定 PyCharmでDjangoのPostgreSQLをGUIで操作するための設定方法です。Djangoには管理サイトが用意されていますが、プログラムの実行中にデ […]
下記のdeep fakeを導入しようとしたら仮想環境作成でかなり困ったので記録しておく。 https://knowledge.sakura.ad.jp/26769/ 試したこと Docker まずdockerでpytho […]
リモートのファイルをローカルのデスクトップにコピー リモートサーバーにSSH鍵でログインして、ファイルをローカルのマシンにコピーする方法です。今回はリモートサーバーにダンプしたsqlファイルをデスクトップにコピーします。 […]
Pythonのenumerate関数でfor文のインデックスを取得 enumerate関数を使うとPythonでforを書くときに処理毎にカウントアップしたり、値を代入したりといった処理が簡単にできるので便利です。 実際 […]
サイトのカラーリングを青と黄色のウクライナカラーにしました ロシアによるウクライナ侵攻の早期停戦を願ってサイトのカラーリングをウクライナ国旗をイメージした青と黄色のウクライナカラーにしました
衣服の図面画像を読み込ませるとその種類を返すシステムを作成した。 学習モデルについて 画像から輪郭だけを抽出した輪郭画像と、オリジナル画像の2つを入力データにすることにした。 例えばTシャツならTの字になっているし、スカ […]
今回、画像分類で精度を高めるために複数データの入力できる学習モデルを作成した。その経緯から始めて実際のモデリングまでを書くことにする。 前提 今回は洋服の図面を読み込み、それがなんの種類かを判別するCNNを作成した。 図 […]
pythonのOpenCVで輪郭を上手く抽出することができなかったが、いくつかの改善点により上手く行った経緯をここに書き残しておく。 改善前 これは50×50のスカートの画像である。単にfindcontourし […]
Jupyter NotebookでもBlackでコードフォーマット コードの可読性を上げて保守性を高めたり、コードの属人化を防いで生産性を向上させるためのルール(コーディング規約)に則った開発を行うために、ファントムでは […]
PythonのRequestsを使ってSlackに通知 フォームから送られた内容やプログラムの処理結果や途中結果をSlackに通知する方法です。 以下のコードのBOT USER TOKENとCHANNEL NAMEを任意 […]
2022年度 採用についてのお知らせ 概要2022年度の採用募集を開始します。(フルタイム、副業問わずビデオ会議等で意見交換からでもOKです。) 募集職種・インフラエンジニア・ウェブアプリケーションエンジニア・機械学習エ […]
Pythonのf文字列を使った書式パターン この記事で紹介したf文字列を使った文字列の操作ですが、文字列に変数を埋め込む際に書式を指定できます。0埋めして文字数を揃えたり、カンマで桁を区切ることも可能です。 カンマで桁区 […]
Pythonのf文字列を使った文字列の操作 Pythonのf文字列は{1}や{a}のように変数を{}(波括弧)で囲うことで、文字列の中に変数を挿入できるので直感的な記述ができるようになります。従来のように複数の変数や文字 […]
Pythonのargparseでコマンドライン引数をパース argparseモジュールを使って、Pythonを実行する際にコマンドライン引数を指定してプログラム内に情報を渡す方法です。 引数によって処理を変えたり、別々の […]
Announcement about Internships for 2022 日本語のページ OverviewWe’re now accepting applications for full remote […]
2022年度 インターンシップについてのお知らせ For English page 概要2022年度のインターンシップの募集を開始します。 募集職種・インフラエンジニア・ウェブアプリケーションエンジニア・機械学習エンジニ […]

https://shuhoyo.hatenablog.com/entry/nogizaka46-lyrics-nlp
上記サイトを参考にBERT+UMAPを実装してみた。
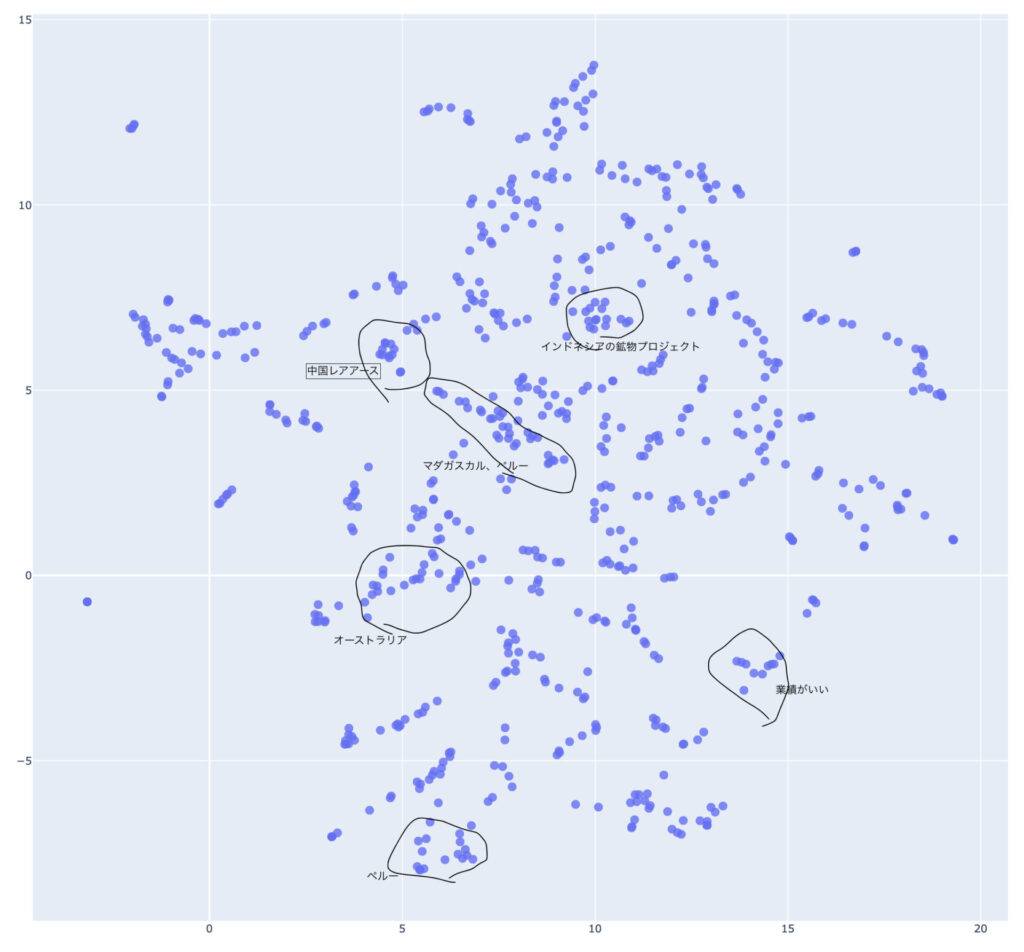
BERTとは自然言語処理の1手法のことだ。 BERTを使った処理の流れを説明すると、まず文章データはJUMAN ++によって単語の列に変換される。 単語の列はBERTによって分散表現と呼ばれる1024次元ベクトルに変換される。 このベクトルを入力データにした機械学習モデルを作ることで、全体としては自然言語モデルになる。
例えば入力値1024で出力値2のNNモデルを作成し、教師データを文章がポジティブなら[1,0],ネガティブなら[0,1]とするような学習モデルを作れば、 全体としては文章を見てネガポジを判定するモデルになる。
今回はこの分散表現をUMAPによって次元削減してみる。 次元削減をすることで、本来BERTによって数値化された文章は1024次元で人の目には理解できないものを、文章同士の位置関係を保ったまま2次元に落とし込むことができる。 これにより、BERTがどの文章同士を似ていると判断したのか分かるわけだ。
実装は上のサイトのように実行しようとしたが、うまく行かない箇所があったので下記も参考にした。
https://snowman-88888.hatenablog.com/entry/2020/08/21/055414
また、入力する文章は次のサイトをスクレイピングした。
見たところ、国ごと、鉱物ごとなどに纏まっているような感じはある。

群馬県でPythonを使ったAIやソフトウェアを開発している株式会社ファントムが運営しています。