Python
ツイートを位置情報でプロットして時系列に纏めるtapiokaHeatmapの解説
ツイートを位置情報でプロットして時系列に纏めるtapiokaHeatmapの解説 今回はタピオカのツイート数を位置情報でプロットして時系列に纏めるソースコードについて解説する。 ソースコードは下記のgithubにあるので […]
Filter by Category
ツイートを位置情報でプロットして時系列に纏めるtapiokaHeatmapの解説 今回はタピオカのツイート数を位置情報でプロットして時系列に纏めるソースコードについて解説する。 ソースコードは下記のgithubにあるので […]
桐生イノベーションEXPO 2021に弊社代表の石井が登壇しました 2021年10月17日(日)に桐生市市民文化会館(シルクホール)で「桐生イノベーションEXPO 2021」に弊社代表の石井が登壇しました。 開催概要 桐 […]
GitHub ActionsでAmazon Lightsailに自動でデプロイする方法 本記事ではGitHub上のリポジトリのmainブランチに変更(コミットやマージなど)があった際に、サーバー側からgit pullを実 […]
Dockerで起動したDjangoプロジェクトをPycharmのデバッグモードで起動 Dockerで起動したDjangoプロジェクトをPycharmのデバッグモードで起動して、ブレークポイントを設定して任意の行でプログラ […]
2021年の夏季休業のお知らせ 誠に勝手ながら、弊社では下記日程を夏季休業とさせていただきます。 夏季休業期間 2021年8月13日(金)~2021年8月16日(月) 期間中にいただきましたお問い合わせにつきましては、夏 […]
Docker環境にGitHubリポジトリをクローンして開発する Djangoを含んで起動させるDockerプロジェクトの例はいくつか見つかりましたが、Docker環境に別で開発しているリポジトリをクローンして開発を進める […]
pipenv shellをしてもactivateできない pipenvで作った仮想環境に出たり入ったりを繰り返していると、pipenv shellをしても以下のようにShell for UNKNOWN_VIRTUAL_E […]
WARNING: `pyenv init -` no longer sets PATH. pyenvが入っているzsh環境(Mac)でターミナルの起動時に以下のエラーが出るようになりました。今回はDjangoのプロジェク […]
40分でUbuntu Nginx PostgreSQL Django Gunicornの環境構築 VPSへのログイン(新規タブ) OSの初期設定(アップデート、アップグレード) 新規ユーザーを追加 新しく追加したユーザー […]
生産効率を上げる方法について筆者が利用している環境を紹介する。前提として、生産効率を高める最も単純な方法はマウスを使わないことだ。したがって、マウスを使わない環境を整備することがまず求められる。次に導入する4つそれぞれの […]
OpenCVで複数の動画を連結する 複数の動画素材を結合したり、GoProで長時間撮影した時に約4GB毎に分割される動画ファイルを結合して一つの動画を書き出す方法です。 コードはGitHubリポジトリにあげています。 開 […]
MEDぐんま 2021に出展しました 2021年5月9日(日)にMEDぐんま 2021に出展しました。 開催概要 ◆MEDぐんま 2021会期: 2021年5月9日(日)会場: 群馬会館
2021年ゴールデンウィーク休業のお知らせ 平素は格別のお引立てを賜り、厚く御礼申し上げます。 誠に勝手ながら、弊社では下記日程をゴールデンウィーク休業とさせて頂きます。 2021年4月29日(木)~ 2021年5月 […]
SDGsぐんまビジネスプラクティスに選定されました 介護現場での「人とテクノロジーの協業」が業務時間の節約や精神的なゆとりの創出につながり、さらには利用者やスタッフ間の豊かなコミュニケーションを生み出し、全ての利用者が本 […]
2021年 長期インターン募集のお知らせ 概要2021年度の長期インターン採用の募集を開始しました。 募集職種・インフラエンジニア・ウェブアプリケーションエンジニア・UI/UXデザイナー・グラフィックデザイナー 想定給与 […]
Pythonでファイルをアップロードする 画像をPOSTして結果を返すプログラムやファイルをアップロードして機械学習の推論を試す時に、ブラウザからFormを使ってアップロードすることもできますが、Pythonでファイルの […]
django-import-exportで管理画面からCSVをインポート 情報を登録する際に一件づつ入力せずにCSVからまとめてインポートして登録が行えるので初期情報を登録する時などに便利な方法です。 コードはGitHu […]
OSError: No translation files found for default language このエラーはDjangoで設定言語が間違ってる時に発生するエラーです。 settings.py setti […]
前回の内容が古くなってしまったので2021年版に更新します。 Dockerを使ってシンプルなDjangoとPostgreSQLの開発環境を構築する方法の2021年版です。以下の点が前回より変わった点です。・Volumeを […]
Pythonのrandomモジュールでランダムな小数・整数を生成 Pythonで乱数(ランダムな小数や整数)が生成できる、randomモジュールの使い方を説明します。 開発環境 float型の乱数を生成(1) float […]

今回はタピオカのツイート数を位置情報でプロットして時系列に纏めるソースコードについて解説する。
ソースコードは下記のgithubにあるので各自ダウンロードしていただきたい。
https://github.com/FANTOM-INC/tapiokaHeatmap
次の画像はこのコードを実行してえられる時系列データのうち、タピオカツイートの最も多い月と少ない月の地理データである。
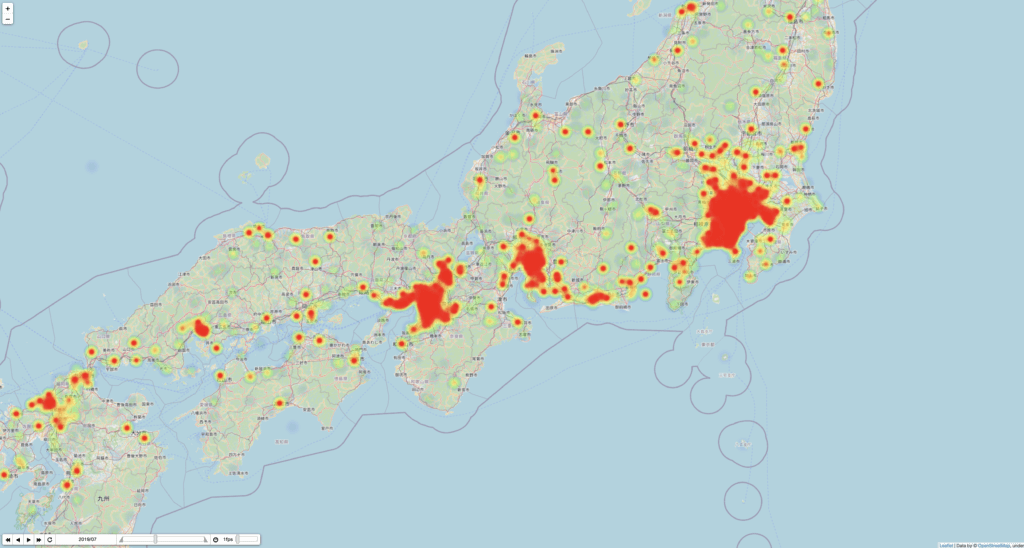
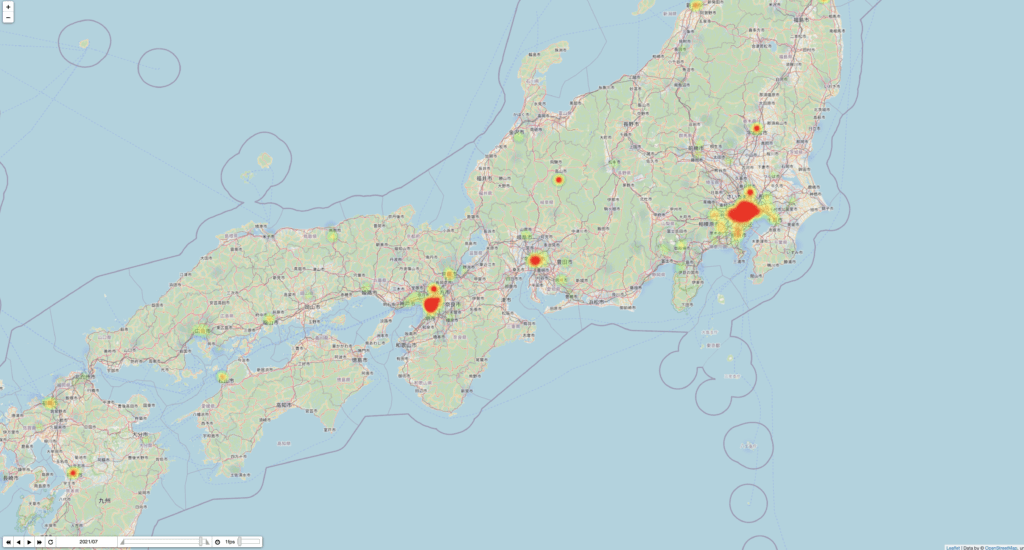
まず、twitter APIはv1.1とv2が混在しており、full-archiveはv1.1でないと利用できないことに注意する。
有料版のツイッターを利用するためには次の事前準備が必要になる。
class twitter_api:
def __init__(self):
#取得した認証キーを設定
self.CONSUMER_KEY = os.environ['CONSUMER_KEY']
self.CONSUMER_SECRE = os.environ['CONSUMER_SECRE']
self.ACCESS_TOKEN = os.environ['ACCESS_TOKEN']
self.ACCESS_SECRET = os.environ['ACCESS_SECRET']
self.api_count = 100
self.twitter = OAuth1Session(self.CONSUMER_KEY, self.CONSUMER_SECRE, self.ACCESS_TOKEN, self.ACCESS_SECRET)
self.url = "https://api.twitter.com/1.1/tweets/search/fullarchive/hogehoge.json"
self.Reshape_data = Reshape_data()
#APIを叩いてデータを取得する
def get_data(self,params):
res = self.twitter.get(self.url, params = params)
return res
def run(self):
next_token = ''
for i in range(self.api_count):
if next_token == '':
params = {'query' : 'タピオカ has:geo -is:retweet', #検索したいワード
"maxResults" : "500",
"fromDate":"201901010000"}
else:
params = {'query' : 'タピオカ has:geo -is:retweet', #検索したいワード
"maxResults" : "500",
"fromDate":"201901010000",
'next':next_token}
res = self.get_data(params)
r = json.loads(res.text)
tweet_datas = r['results']
self.Reshape_data.save_csv(tweet_datas,i)
if 'next' in r.keys():
next_token = r['next']
with open('next_token.txt', mode='w') as f:
f.write(next_token)
else:
next_token = ''
time.sleep(10)この部分がメイン処理である。やっていることは単純で、paramsに必要事項を入力してself.get_data(params)すればAPIにリクエストを送って結果が帰ってきて、json.dumpでdict形式にしpandasでpickleファイルに保存するというだけである。
今回はタピオカの単語が含まれたツイートを探すのでqueryはタピオカになる。ただし、位置情報がほしいためhas:geoを付け加えておく。
このあたりのオペレーターは非常に多く提供されているので公式を参照するとよい。
https://developer.twitter.com/en/docs/twitter-api/premium/search-api/guides/operators
このとき、self.urlのエンドポイントは自身が事前準備で設定したenvironmentsにすることを忘れないようにしておく。今回はfull-archiveであるが、30-daysを取得したいならエンドポイントの/fullarchive/を変更するだけだ。
また、事前準備で入手した各トークンは.envファイルに追記しておく。
twitter APIの仕様として、paramsで検索したときに上限を超えるツイートが存在する場合にnext_tokenがresultsに入るようになっている。このnext_tokenをparams[‘next’]に入れることで、次のツイート群を取得できるというわけだ。
したがって、next_tokenが存在する場合にnext_token.txtに保存しておいて、next_tokenが存在する場合はparamsに追加するようにしてある。
こうしてえられたdictをpandasのDataFrame形式にするわけだが、twitterのresultsはdictの中にdictが入った多重構造になっているのでflatten_dictによって平坦化し、2次元のDataFrame構造にしている。
このコードは以下を参考にした。
https://www.haya-programming.com/entry/2018/08/30/135041
このget_twetter.pyを実行することで、pklsフォルダに0.py, 1.py, …と追加されてゆく。
def concat_df(self, max_file_num):
df = pd.read_pickle('pkls/0.pkl')
for i in range(1,max_file_num):
df = pd.concat([df,pd.read_pickle('pkls/{}.pkl'.format(i))],axis=0,join='inner',ignore_index=True)
return df
def format_df(self,df):
DataFrame = pd.DataFrame([],columns = {}).dropna()
DataFrame['created_at'] = df[('created_at',)].map(lambda x:datetime.datetime.strptime(x,'%a %b %d %H:%M:%S +0000 %Y'))
DataFrame['prefecture'] = df[('place', 'name')]
DataFrame['latitude'] = df[('place', 'bounding_box', 'coordinates')].map(lambda x: np.array(x)[0,:,1].mean() if type(x) == list else x)
DataFrame['longitude'] = df[('place', 'bounding_box', 'coordinates')].map(lambda x: np.array(x)[0,:,0].mean() if type(x) == list else x)
DataFrame['text'] = df[('text',)]まず、concat_dfによってpklsフォルダに入っている0.pkl, 1.pkl, …を結合して大きな1つのDataFrameにする。
その後、format_dfによってcreated_atをstrからdatetimeに変換したり、緯度経度を取り出したりする。
このとき、緯度経度の情報は(‘place’, ‘bounding_box’, ‘coordinates’)に入っているが、これは緯度経度の4つ組listか1つ組listのいずれかになっている。
前者の場合、4つ組による長方形の範囲内のどこかでツイートがされたということであり、後者の場合はその地点でツイートがされたということである。
for k in [2019,2020,2021]:
start_date = datetime.datetime(k,1,1,0,0,0)
for i in range(self.split_num):
now_date_s = start_date + relativedelta(month=1+i*int(12/self.split_num))
now_date_e = start_date + relativedelta(month=(i+1)*int(12/self.split_num))
DataFrame_sep_month = DataFrame[(now_date_s<= DataFrame['created_at']) & (DataFrame['created_at'] <= now_date_e) ]
DataFrame_sep_month = self.DataFrame_groupby(DataFrame_sep_month,'text')
column_name = now_date_s.strftime('%Y/%m')
df_timeSeries = pd.concat([df_timeSeries,DataFrame_sep_month[['count']].rename(columns={'count':column_name})],axis=1)
time_columns.append(column_name)
df_coordinates = self.DataFrame_groupby(DataFrame,'text')[['latitude','longitude']]
df_timeSeries = pd.concat([df_timeSeries,df_coordinates],axis=1)
df_timeSeries = df_timeSeries.fillna(0)
heat_map_data = []
for idx in time_columns:
heat_map_data_per_month = []
for i in range(len(df_timeSeries)):
df_timeSeries_sep = df_timeSeries[['latitude','longitude',idx]].iloc[i]
if df_timeSeries_sep[idx] != 0:
heat_map_data_per_month.append([df_timeSeries_sep['latitude'],df_timeSeries_sep['longitude'],df_timeSeries_sep[idx]])
heat_map_data.append(heat_map_data_per_month)この部分は以下を参考にした。
https://qiita.com/hcpmiyuki/items/e16edc17805c94c03651
最終的には
[latitude, longitude, 数値]を1地点として複数地点を纏めた
[[latitude1, longitude1, 数値1], [latitude2, longitude2, 数値2], …]を1時刻とした
[[時刻1], [時刻2], …]という形式でfoliumに送ればなんでもよい。
これを実行すればタピオカの盛者必衰のさまを表示することができる。

群馬県でPythonを使ったAIやソフトウェアを開発している株式会社ファントムが運営しています。
Comments