Python
BERT+UMAPを実装した
https://shuhoyo.hatenablog.com/entry/nogizaka46-lyrics-nlp 上記サイトを参考にBERT+UMAPを実装してみた。 BERTとは BERTとは自然言語処理の1手法の […]
https://shuhoyo.hatenablog.com/entry/nogizaka46-lyrics-nlp
上記サイトを参考にBERT+UMAPを実装してみた。
BERTとは自然言語処理の1手法のことだ。 BERTを使った処理の流れを説明すると、まず文章データはJUMAN ++によって単語の列に変換される。 単語の列はBERTによって分散表現と呼ばれる1024次元ベクトルに変換される。 このベクトルを入力データにした機械学習モデルを作ることで、全体としては自然言語モデルになる。
例えば入力値1024で出力値2のNNモデルを作成し、教師データを文章がポジティブなら[1,0],ネガティブなら[0,1]とするような学習モデルを作れば、 全体としては文章を見てネガポジを判定するモデルになる。
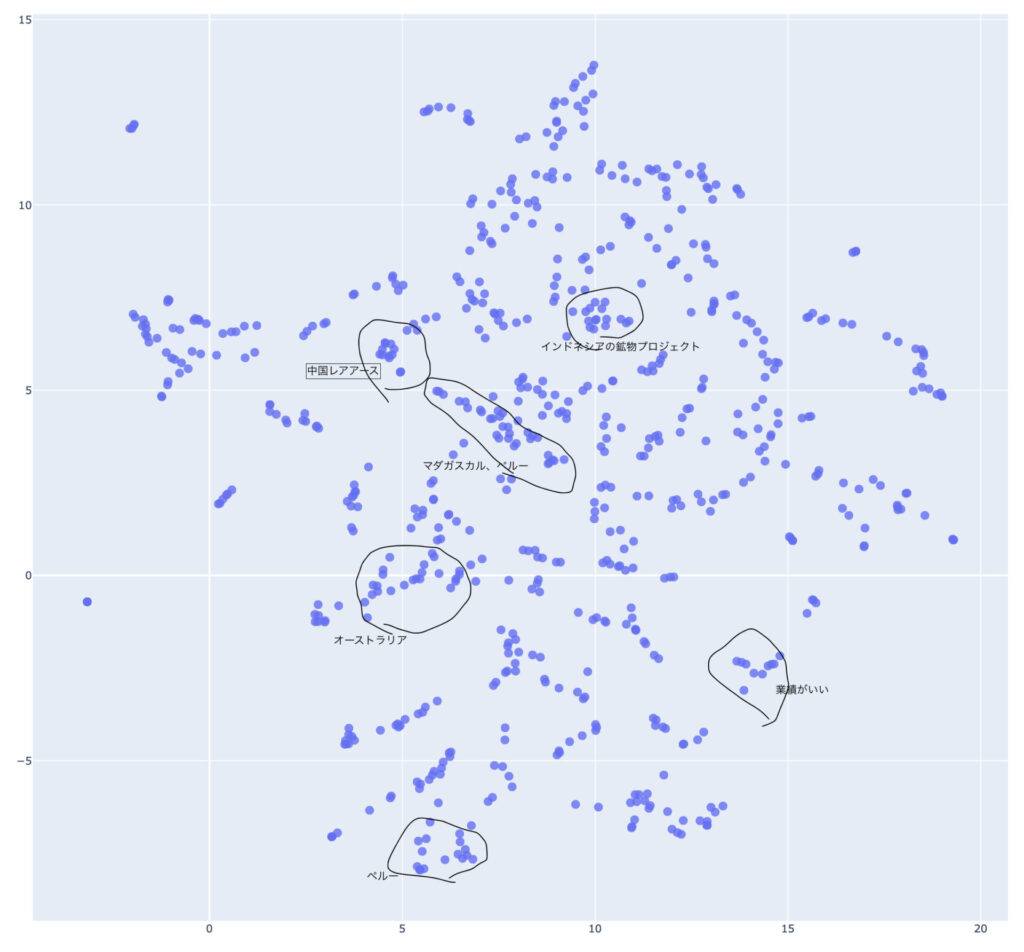
今回はこの分散表現をUMAPによって次元削減してみる。 次元削減をすることで、本来BERTによって数値化された文章は1024次元で人の目には理解できないものを、文章同士の位置関係を保ったまま2次元に落とし込むことができる。 これにより、BERTがどの文章同士を似ていると判断したのか分かるわけだ。
実装は上のサイトのように実行しようとしたが、うまく行かない箇所があったので下記も参考にした。
https://snowman-88888.hatenablog.com/entry/2020/08/21/055414
また、入力する文章は次のサイトをスクレイピングした。
見たところ、国ごと、鉱物ごとなどに纏まっているような感じはある。
群馬県でPythonを使ったAIやソフトウェアを開発している株式会社ファントムが運営しています。